
Чому ChatGPT погано розуміє українську?

Чимало українців полюбили використовувати чат-боти, як-то ChatGPT від OpenAI, як помічників у роботі. Але для декого й досі питання: чому, якщо «спілкуєшся» з чат-ботом англійською, він – досить пристойний помічник. Тільки-но пишеш запит українською, можеш отримати набір вигаданих фактів. Богдан Питайчук, chief AI officer у Gathers та дослідник ШІ, пояснює, чому чат-ботам так складно ладнати з українською мовою, та коли вони зможуть нею вільно «розмовляти» із користувачами.
Англійську мову називають найпопулярнішою мовою програмування. Такі тези стали актуальними завдяки ChatGPT та іншим схожим інструментам на основі генеративного штучного інтелекту (AI), адже всі вони набагато краще працюють саме з англійською мовою, ніж з будь-якою іншою.
ChatGPT показує, що сила генеративного AI доступна буквально кожній людині, у якої є інтернет. Нейромережі допомагають писати, продумувати маркетингові стратегії, обслуговувати клієнтів та загалом під управлінням професіонала стають важливими інструментами, що якісно покращують та пришвидшують роботу.
Проте, якщо ви пробували користуватися ChatGPT українською, то напевне отримали незадовільний результат і вже встигли розчаруватися.
Чат-бот розуміє вас, навіть може видати відносно непогану відповідь, проте стабільно на високому рівні українською він працювати не буде. Про якісну допомогу у розвʼязанні робочих завдань узагалі не йдеться.
Враховуючи, що технологія постійно розвивається і невдовзі повністю змінить ринок праці, важливо розуміти, як вона працює.
Чому ChatGPT чи інші генеративні AI-інструменти чудово працюють англійською і набагато гірше українською чи іншими мовами? Та чи зміниться це в майбутньому? Спойлер: так, навіть поясню чому.
Токени – ключ до сприйняття світу нейромережами
Найпростіше пояснення поганої якості текстів українською – мала кількість україномовних даних, на яких навчався ChatGPT. Частково це правда, проте насправді це не головна проблема нейромереж, адже ці дані насправді генералізуються.
Як це працює? Наприклад, під час тренування AI аналізує величезну кількість текстів англійською про котів та собак. Після цього йому дають схожі тексти українською, і зрештою нейромережа розуміє, що cat – це кіт, а dog – це собака.
Нині штучний інтелект іде ще далі. Нещодавно один з AI-інструментів Google, який у компанії тренували багатьма мовами, навчився розуміти та відповідати мовою, якої не було в його базі. Тобто модель вловила щось (дослідники й досі не знають, як це сталося), що є характерним для всіх мов, і це дозволило їй розширити свою базу без жодних додаткових даних.
Тому проблема відсутності великої кількості україномовних даних, звичайно, відіграє свою роль, проте не є коренем проблеми.
Перше, що необхідно знати про нейромережі, – вони не сприймають світ як люди. У них немає очей, вух, носа чи шкіри – AI все «бачить» через числа.
Якщо спростити, інтелектуальність AI проявляється у пошуку залежності між послідовностями чисел. Текст, який ми пишемо у діалогове вікно чат-бота, він бачить у вигляді чисел, або, як їх називають у професійному середовищі, токенів.
Токен – це не просто числові замінники слів чи літер. Це фундаментальні блоки, на основі яких модель вивчає, розуміє та обробляє мову. Саме тут виникає найбільша та найважливіша різниця: ChatGPT натренували на токенах, заточених під англійську мову.
Тому англійські слова «токенізуються» за приблизною формулою «один токен = одне слово». Водночас ті самі слова чи речення, написані українською мовою, використовують набагато більше токенів.
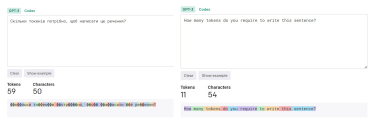
Англійські слова «токенізуються» за приблизною формулою «один токен = одне слово». Водночас ті самі слова чи речення, написані українською мовою, використовують набагато більше токенів.
Речення англійською мовою складається з 10 слів, 54 знаків та 11 токенів. Українською – сім слів, 50 знаків та 59 токенів.
Спілкуючись із чат-ботом будь-якою мовою, крім англійської, ми використовуватимемо більше токенів. Мови, в основі яких лежить латинка (наприклад, італійська чи французька), витрачатимуть приблизно вдвічі більше токенів. Кирилиця ж для сучасних нейромереж поки що є дуже важкою, а тому часто можна побачити, коли навіть одна буква «з’їдає» кілька токенів.
Враховуючи обмежене контекстне вікно ChatGPT (кожен діалог – це 8000 токенів), чат-бот витрачає набагато більше пам’яті лише на обробку запиту, не кажучи вже про генерацію та видачу результату. Через це він швидко «забуває» основну тему та починає галюцинувати, тобто вигадувати інформацію, аби написати хоч щось.
Наприклад, якщо ви попросите ChatGPT написати вірш англійською, то отримаєте загалом непоганий результат – із гарними римами та креативними епітетами. Якщо ж захочете отримати вірш українською, творіння штучного інтелекту навряд чи вам сподобається.
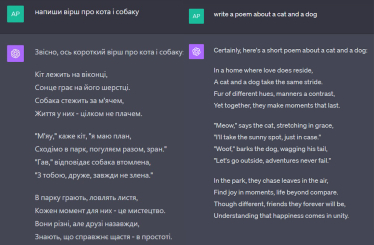
Якщо ви захочете отримати вірш українською, творіння штучного інтелекту навряд чи вам сподобається.
Ключ до розуміння цієї проблеми – комбінація токенів. Якщо один токен репрезентує одне слово, як у випадку з англійською, то нейромережа може легко знайти залежності між цими словами, поєднавши їх у твір, що римується.
Коли ж на одну букву витрачається одразу кілька токенів, для нейромережі знайти цей зв’язок між словами набагато важче. Саме тому ChatGPT набагато довше та менш якісно генерує тексти українською (причому не тільки вірші, а й звичайні).
Правильно формулюйте завдання, тобто якісно прописуйте промпти – текстові підказки для нейромережі, якими ви направляєте штучний інтелект блукати вашими завданнями.
Завдяки своєму інтелекту, а також широкому спектру різноманітних можливостей для сприйняття світу ми звикли розуміти один одного з пів слова. У своєму спілкуванні люди навчилися додумувати одне за одного й одразу розуміти, що хоче сказати співрозмовник.
Така комунікація є звичайною для нас, проте не для нейромереж. Їм важливо ставити чіткі завдання, з усіма деталями, про які під час розмови з іншими людьми ми навіть не замислюємось.
Чи буде ChatGPT краще працювати з українською
Під час тренування кожна нейромережа вивчає величезну кількість даних. Їй показують дуже багато текстів, у яких AI шукає взаємозалежності.
Коли в AI-інструменту вже є певна база, йому показують нові дані (Evaluation Dataset), які він не бачив раніше, щоб перевірити, наскільки добре він їх розуміє та генерує схожі фрази.
Цей принцип схожий на те, як навчаються люди: спочатку ми вчимо певні правила, а потім розв’язуємо задачі для закріплення матеріалу.
Влітку один з користувачів Twitter розповів, що OpenAI взяв його українську базу даних саме для виконання такої перевірки. Тепер у майбутньому під час внутрішніх перевірок точності роботи ChatGPT або інших AI-інструментів компанії українська мова матиме більший вплив на цей показник.
Чи означає це, що вже скоро чат-бот буде класно працювати українською? Ні.
Проте поступовий розвиток архітектури нейромереж має привести нас у майбутнє, в якому AI-інструменти працюватимуть з різними мовами набагато краще, ніж зараз.
Йдеться не лише про поліпшення ChatGPT чи інших інструментів. Це важливий виклик, який стоїть перед AI-спільнотою на роки вперед: зробити AI універсальним для якомога більшої кількості людей.


